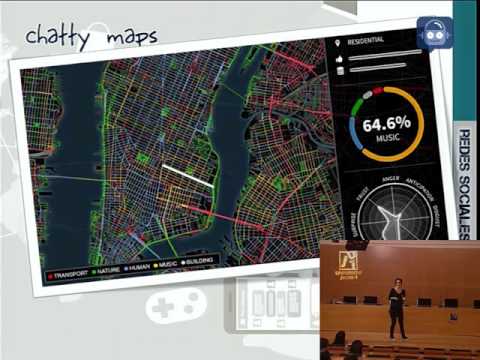
Los usuarios de las redes sociales generan una cantidad de información salvaje de la que podemos disponer para aprender muchas cosas. Durante esta charla veremos cómo recoger esta información de Twitter para construir un mini conjunto de datos con el que entrenar un sistema automático que sea capaz, bueno, más o menos capaz, de identificar tweets que son troleo de los que no lo son. Lo haremos desarrollando un sencillo sistema de procesamiento del lenguaje natural y aprendizaje automático con las super pilas científicas de Python.
Hablaremos de la importancia de escribir código bello y crear gráficas significativas, de la replicabilidad de los experimentos que diseñemos, de difundir el conocimiento y sobretodo de la importancia que tiene crear un entorno seguro y afable donde todos/as podamos participar libremente.
Resumiendo: redes sociales, procesamiento del lenguaje natural, aprendizaje automático, data science, códigos de conducta… Y todo usando nuestra arma favorita: Python. ¡Trolls estáis avisados!
MAITE GIMENEZ
¡Hola! Soy Maite. Graduada en Bellas Artes y estudiante de doctorado en Informática en la Universitat Politècnica de València sobre lenguaje natural y aprendizaje automático.
Soy miembro de la Asociación de Python España y soy una Pylady. Aspirante a BDFL, entusiasta del código libre, de Python y de los gatos. Mi superpoder es la empatía, que es el peor superpoder del mundo.